一种自动识别书面文本中特定单词的情感极性的模型
近年来,计算机科学家一直在努力开发有效的情绪分析模型。这些模型旨在分析句子或较长的文本,并自主确定其潜在的情感基调。
除了表达整体情感基调外,文本还可以包含充满积极或消极情绪的单个单词,以及中性单词。例如,如果我们在抱怨某事,那么描述所讨论事物的词很可能会被指控为负面情绪。
识别句子中特定单词的“情感极性”(即消极或积极的情感内涵)的任务被称为基于方面的情感分析(ABSA)。虽然这项任务对人类来说可能是直观和简单的,但使用计算模型来解决它可能更具挑战性。
中国安徽理工大学的研究人员最近开发了一种旨在有效完成ABSA任务的新模型。该模型在《连接科学》的一篇论文中介绍,基于一种称为轻量级多层交互式注意力网络(LMIAN)的机器学习算法。
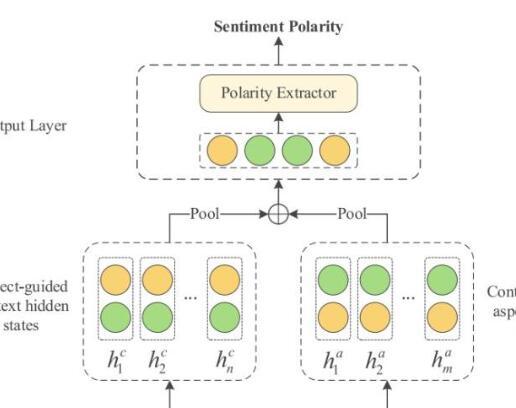
“现有的研究已经认识到ABSA中交互式学习的价值,并开发了各种方法,通过交互式学习精确地建模方面词及其上下文,”Wenjun Zheng,Shunxiang Zhang和他们的同事在他们的论文中写道。“然而,这些方法大多采用浅层交互的方式来建模方面词及其上下文,这可能导致缺乏复杂的情感信息。为了解决这个问题,我们为ABSA提出了一个轻量级多层交互式注意力网络(LMIAN)。
交互式注意力网络可以通过注意力机制学习注意句子中的特定单词,这允许他们将这些单词与发现它们的整体语言上下文联系起来。作为他们最近研究的一部分,Zheng,Zhang和他们的同事训练了其中一个模型来专门学习隐藏在文本中的复杂情感信息,以便它可以检测特定单词的情感极性。
“我们首先使用预先训练的语言模型来初始化词嵌入向量,”Zheng,Zhang和他们的同事在他们的论文中写道。“其次,交互式计算层旨在建立方面词与其上下文之间的相关性。这种相关度由具有神经注意力模型的多个计算层计算得出。第三,我们在计算层之间使用参数共享策略。这允许模型以更低的内存成本学习复杂的情绪特征。
研究人员使用六个公开的情感分析数据集训练和评估他们的模型,其中包含中文和英文文本。这些文本本质上是对产品或服务的在线评论,带有关联的对象和情绪标签(即正面、负面或中性),最终允许团队训练他们的模型。
在这些数据集的初步评估中,该团队的LMIAN取得了非常有希望的结果,识别出准确率超过90%的句子中单词的情感极性,同时消耗的GPU内存比其他网络少。将来,它的性能可以进一步提高,并且还可能与其他文本和情感分析工具集成。
“广泛的实验证明,我们的LMIAN在模型的性能,大小和GPU内存消耗之间实现了更好的平衡,”Zheng,Zhang和他们的同事在他们的论文中总结道。“未来,我们将进一步优化我们的交互式注意力模型,以获得更高的性能和更低的GPU内存消耗。我们的想法之一是将局部特征与方面词进行深度交互,通过减少干扰信息来提高模型性能。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【既简单又好吃的甜品】在快节奏的生活中,很多人想要享受甜品的乐趣,但又担心制作过程复杂、耗时太长。其实...浏览全文>>
-
【既简单又好吃的菜包饭】菜包饭是一道非常受欢迎的家常美食,尤其在亚洲地区广为流传。它不仅制作简单,而且...浏览全文>>
-
【既灬也灬二年级造句】在小学语文学习中,“既……也……”是一个常见的句式,用来表达两个并列的情况或特点...浏览全文>>
-
【既好看又好听的网名】在当今网络社交日益频繁的时代,一个好听又好看的网名不仅能够提升个人形象,还能让人...浏览全文>>
-
【既搞笑又土气的名字有什么】在日常生活中,我们经常会遇到一些让人忍俊不禁、又觉得“土味十足”的名字。这...浏览全文>>
-
【既定是什么意思】2、直接用原标题“既定是什么意思”生成一篇原创的优质内容(加表格形式)在日常生活中,我...浏览全文>>
-
【既的意思是什么】2、直接用原标题“既的意思是什么”生成一篇原创的优质内容,要求:以加表格的形式展示答案...浏览全文>>
-
【既的文言文意思】在文言文中,“既”是一个常见的虚词,具有多种含义和用法,常用于表示时间、状态或结果。...浏览全文>>
-
【既戴帽子又戴眼镜的动漫角色】在众多动漫作品中,一些角色因为独特的造型设计而给人留下深刻印象。其中,“...浏览全文>>
-
【既不缺钱也不缺人的山东】山东省作为中国重要的经济大省,一直以来在经济发展、人口规模和资源储备方面都具...浏览全文>>