学习发展机器学习模型
OpenAI的ChatGPT具有一些令人难以置信的功能,这已经不是什么秘密了——例如,聊天机器人可以写出类似于莎士比亚十四行诗的诗歌,或者为计算机程序调试代码。这些能力是通过构建 ChatGPT 的大规模机器学习模型实现的。研究人员发现,当这些模型变得足够大时,就会出现非凡的能力。
但更大的模型也需要更多的时间和金钱来训练。训练过程涉及向模型显示数千亿个示例。收集如此多的数据本身就是一个复杂的过程。然后是运行许多功能强大的计算机数天或数周来训练可能具有数十亿个参数的模型的货币和环境成本。
“据估计,假设运行ChatGPT规模的训练模型可能需要数百万美元,仅一次训练运行就要花费数百万美元。我们能否提高这些训练方法的效率,以便我们仍然可以在更短的时间内以更少的钱获得好的模型?我们建议通过利用以前训练过的较小语言模型来做到这一点,“麻省理工学院电气工程与计算机科学系助理教授,计算机科学与人工智能实验室(CSAIL)成员Yoon Kim说。
Kim和他的合作者没有丢弃以前版本的模型,而是将其用作新模型的构建块。使用机器学习,他们的方法学会从较小的模型中“增长”较大的模型,从而对较小模型已经获得的知识进行编码。这样可以更快地训练更大的模型。
与从头开始训练新模型的方法相比,他们的技术节省了训练大型模型所需的计算成本的50%。此外,使用 MIT 方法训练的模型的性能与使用其他技术训练的模型一样好,甚至更好,这些模型也使用较小的模型来更快地训练较大的模型。
减少训练大型模型所需的时间可以帮助研究人员以更少的费用更快地取得进展,同时还可以减少训练过程中产生的碳排放。它还可以使较小的研究小组使用这些大型模型,从而可能为许多新进展打开大门。
“随着我们希望使这些类型的技术民主化,使培训更快,更便宜将变得更加重要,”Kim说,他是关于这种技术的论文的资深作者。
Kim和他的研究生Lucas Torroba Hennigen与德克萨斯大学奥斯汀分校的研究生Peihao Wang以及MIT-IBM Watson AI Lab和哥伦比亚大学的其他人一起撰写了这篇论文。该研究将在学习表征国际会议上发表。
越大越好
像 GPT-3 这样的大型语言模型是 ChatGPT 的核心,它是使用称为转换器的神经网络架构构建的。神经网络松散地基于人脑,由相互连接的节点或“神经元”层组成。每个神经元都包含参数,这些参数是在神经元用于处理数据的训练过程中学习的变量。
转换器架构是独一无二的,因为随着这些类型的神经网络模型变得越来越大,它们会获得更好的结果。
“这导致了一场军备竞赛,试图在越来越大的数据集上训练越来越大的变压器。与其他架构相比,变压器网络似乎随着扩展而变得更好。我们只是不确定为什么会这样,“Kim说。
这些模型通常有数亿或数十亿个可学习的参数。从头开始训练所有这些参数是昂贵的,因此研究人员寻求加速该过程。
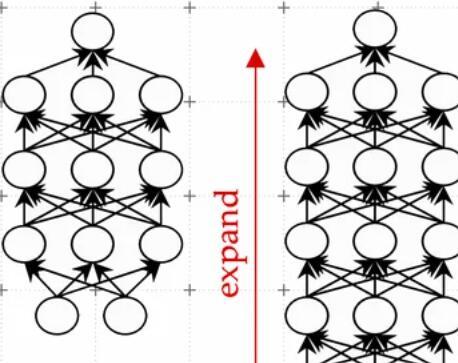
一种有效的技术称为模型增长。使用模型生长方法,研究人员可以通过复制神经元,甚至复制以前版本的网络的整个层,然后将它们堆叠在顶部来增加变压器的大小。他们可以通过向层添加新神经元来使网络更宽,或者通过添加额外的神经元层来使其更深。
Kim解释说,与以前的模型增长方法相比,与扩展变压器中的新神经元相关的参数不仅仅是较小网络参数的副本。相反,它们是较小模型参数的学习组合。
学习成长
Kim和他的合作者使用机器学习来学习较小模型参数的线性映射。此线性映射是一种数学运算,它将一组输入值(在本例中为较小模型的参数)转换为一组输出值(在本例中为较大模型的参数)。
他们的方法,他们称之为学习线性增长算子(LiGO),学习以数据驱动的方式从较小网络的参数扩展较大网络的宽度和深度。
但较小的模型实际上可能相当大——也许它有一亿个参数——研究人员可能想创建一个包含十亿个参数的模型。因此,LiGO技术将线性地图分解成机器学习算法可以处理的更小的部分。
LiGO还可以同时扩展宽度和深度,这使其比其他方法更有效。Kim解释说,用户可以在输入较小的模型及其参数时调整他们希望较大模型的宽度和深度。
当他们将他们的技术与从头开始训练新模型的过程以及模型增长方法进行比较时,它比所有基线都快。他们的方法节省了训练视觉和语言模型所需的计算成本的50%,同时通常可以提高性能。
研究人员还发现,他们可以使用LiGO来加速变压器训练,即使他们无法使用较小的预训练模型。
“令我惊讶的是,与随机初始化、从头开始训练基线相比,包括我们的方法在内的所有方法都做得更好。”金说。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。